Abstract
Attention-based Transformer models have been increasingly employed for automatic music generation. To condition the generation process of such a model with a user-specified sequence, a popular approach is to take that conditioning sequence as a priming sequence and ask a Transformer decoder to generate a continuation. However, this prompt-based conditioning cannot guarantee that the conditioning sequence would develop or even simply repeat itself in the generated continuation. In this paper, we propose an alternative conditioning approach, called theme-based conditioning, that explicitly trains the Transformer to treat the conditioning sequence as a thematic material that has to manifest itself multiple times in its generation result. This is achieved with two main technical contributions. First, we propose a deep learning-based approach that uses contrastive representation learning and clustering to automatically retrieve thematic materials from music pieces in the training data. Second, we propose a novel gated parallel attention module to be used in a sequence-to-sequence (seq2seq) encoder/decoder architecture to more effectively account for a given conditioning thematic material in the generation process of the Transformer decoder. We report on objective and subjective evaluations of variants of the proposed Theme Transformer and the conventional prompt-based baseline, showing that our best model can generate, to some extent, polyphonic pop piano music with repetition and plausible variations of a given condition.
Demo
Audio Samples
| ID | Theme | Real Data | Baseline | Theme Transformer |
|---|---|---|---|---|
| 875 | ||||
| 888 | ||||
| 890 | ||||
| 893 | ||||
| 899 | ||||
| 900 | ||||
| 901 | ||||
| 904 | ||||
| 908 | ||||
| 909 |
Figures
| id | First 24 bars | Melody Embedding Distance |
|---|---|---|
| 875 |  |
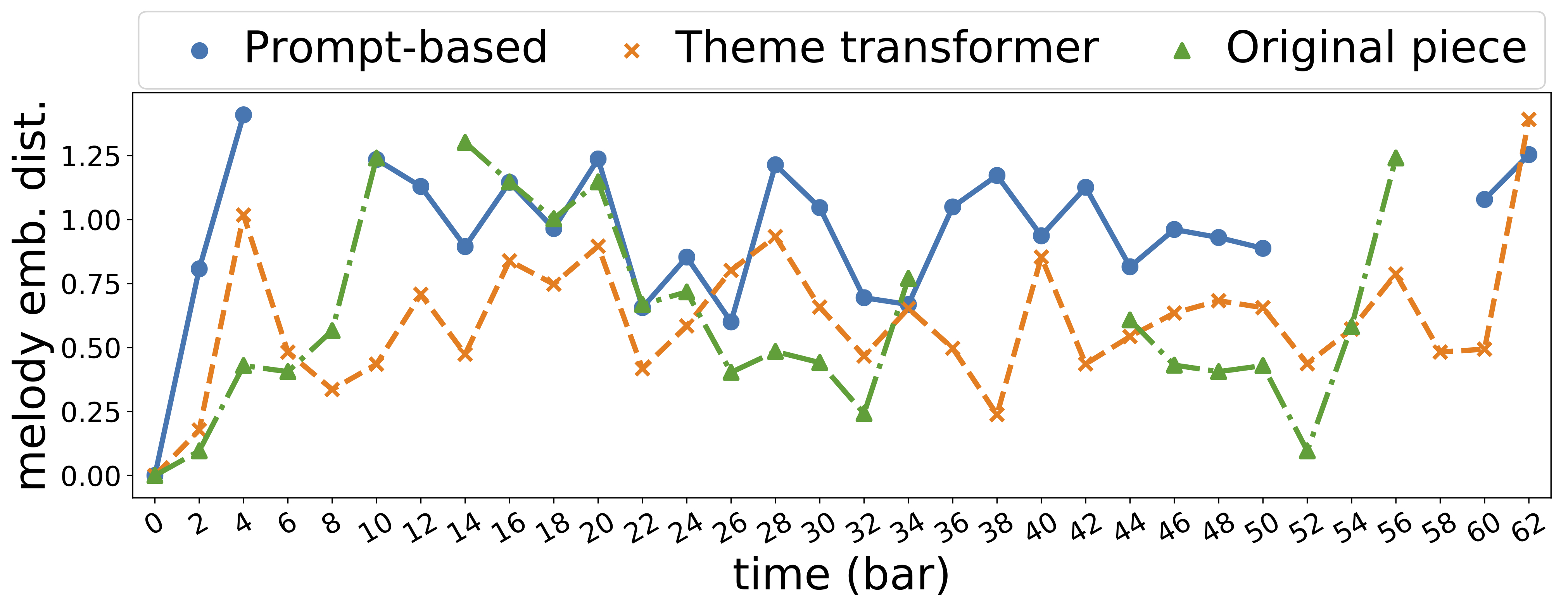 |
| 888 |  |
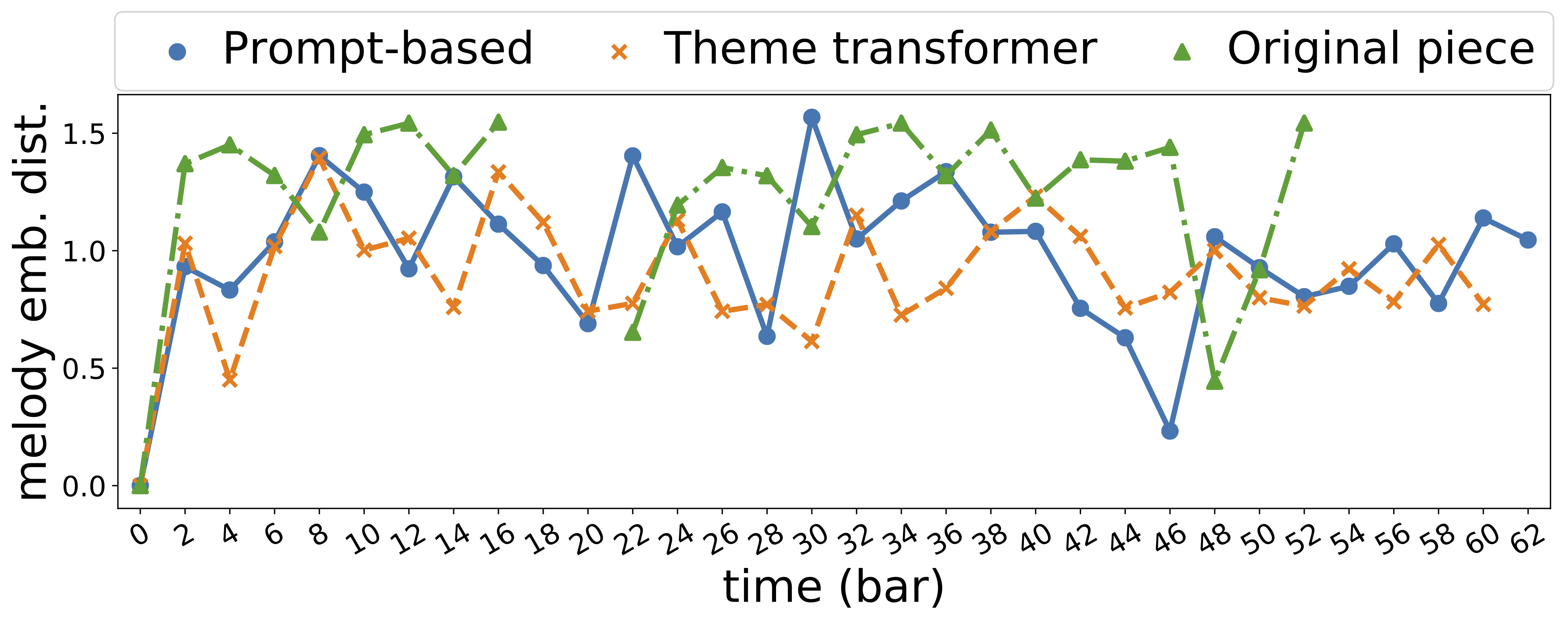 |
| 890 |  |
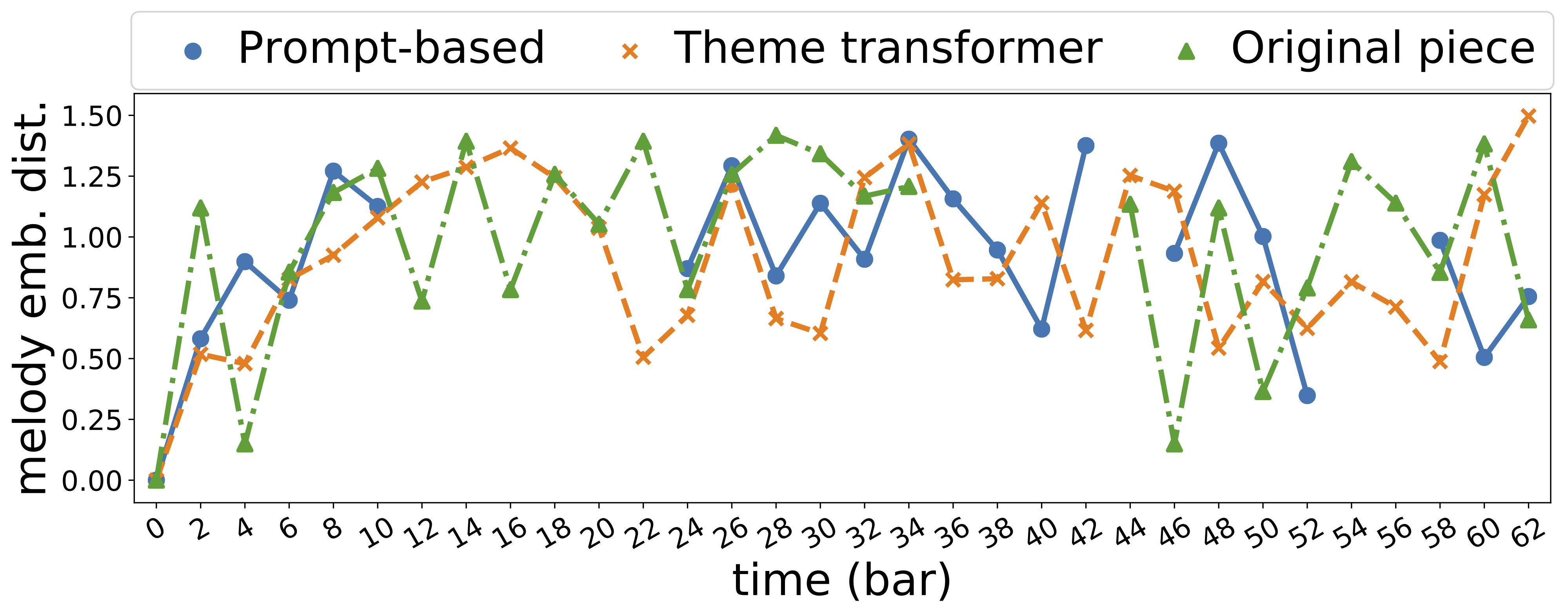 |
| 893 |  |
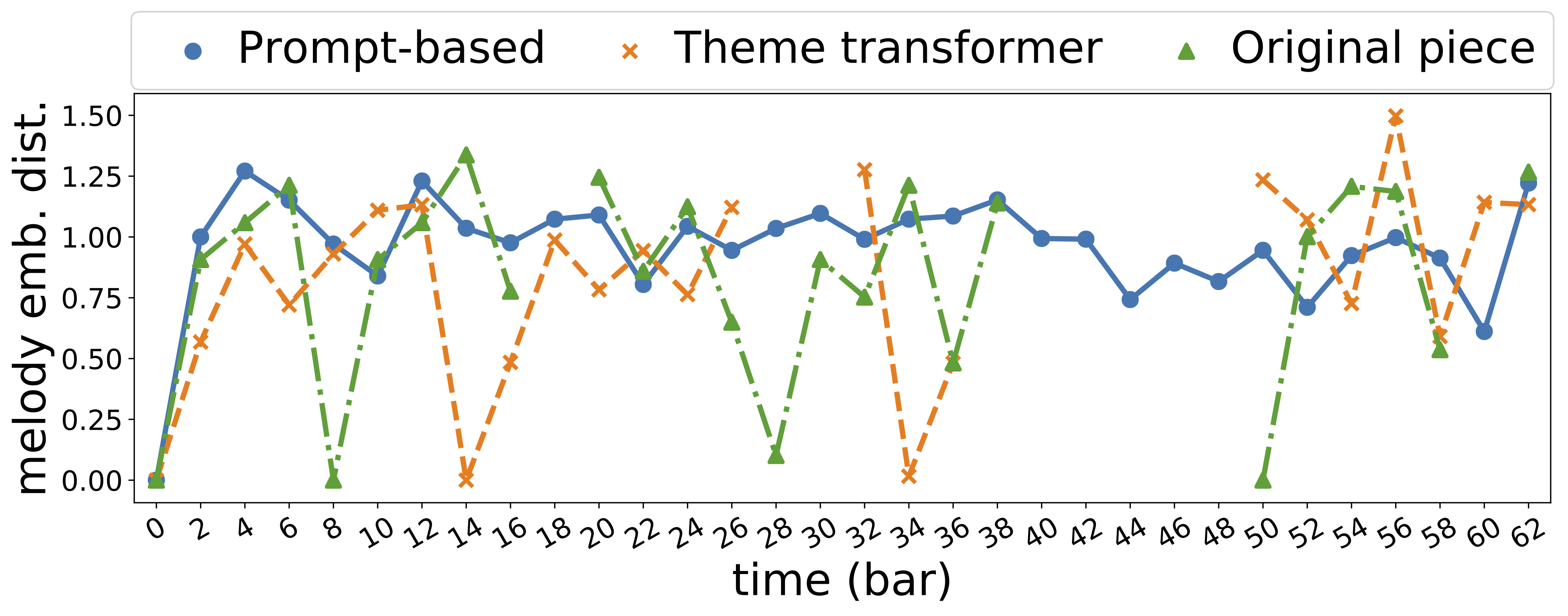 |
| 894 |  |
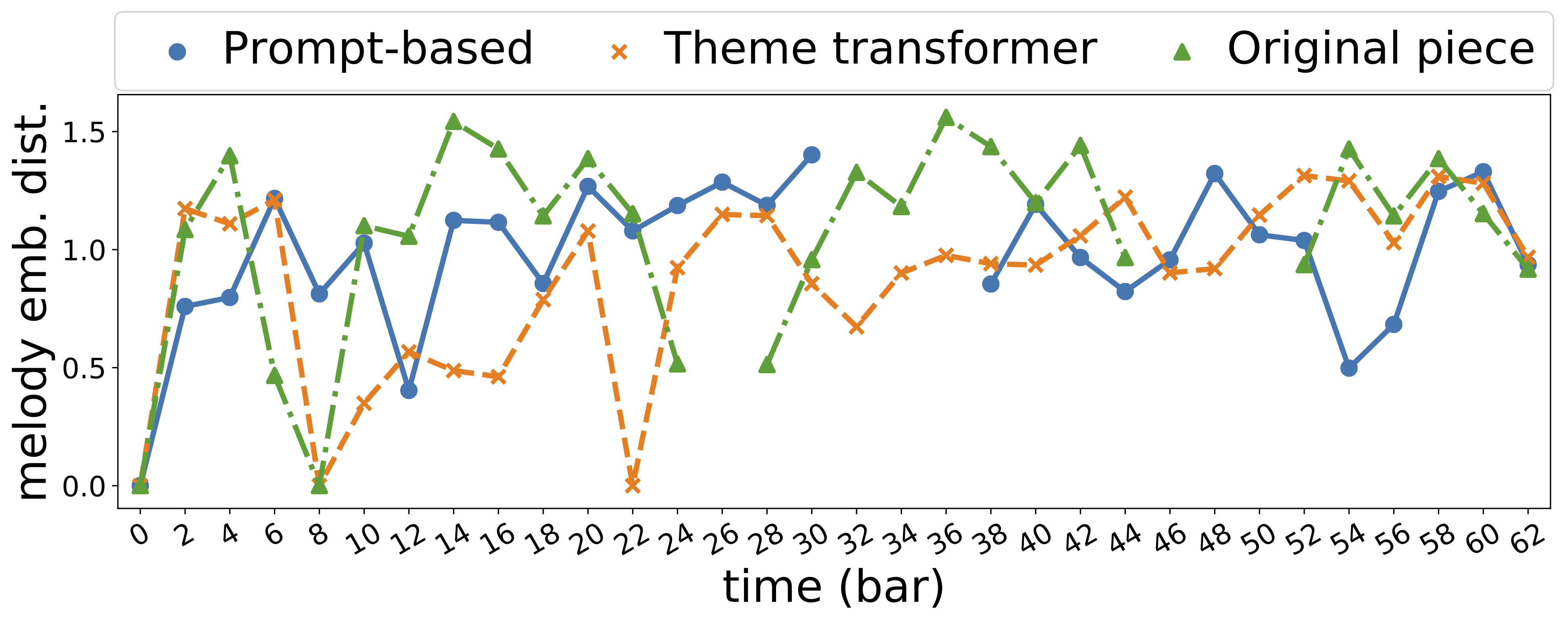 |
| 896 |  |
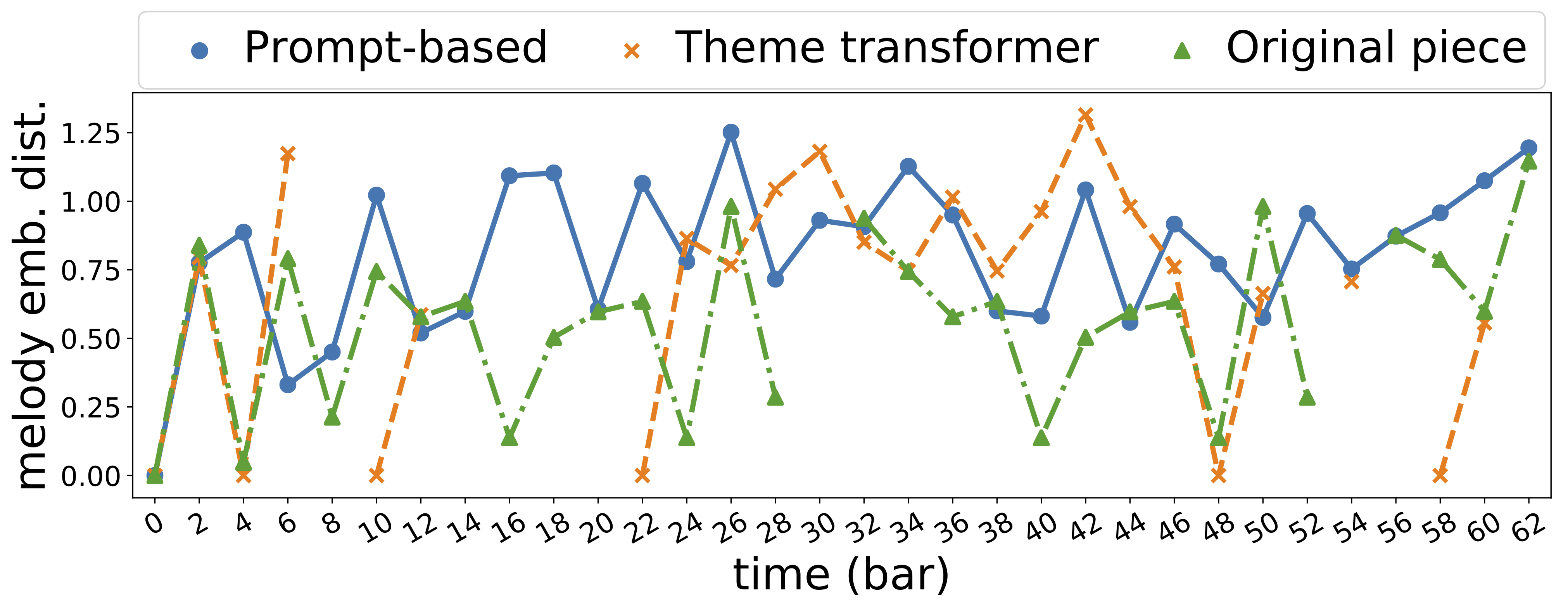 |
| 899 |  |
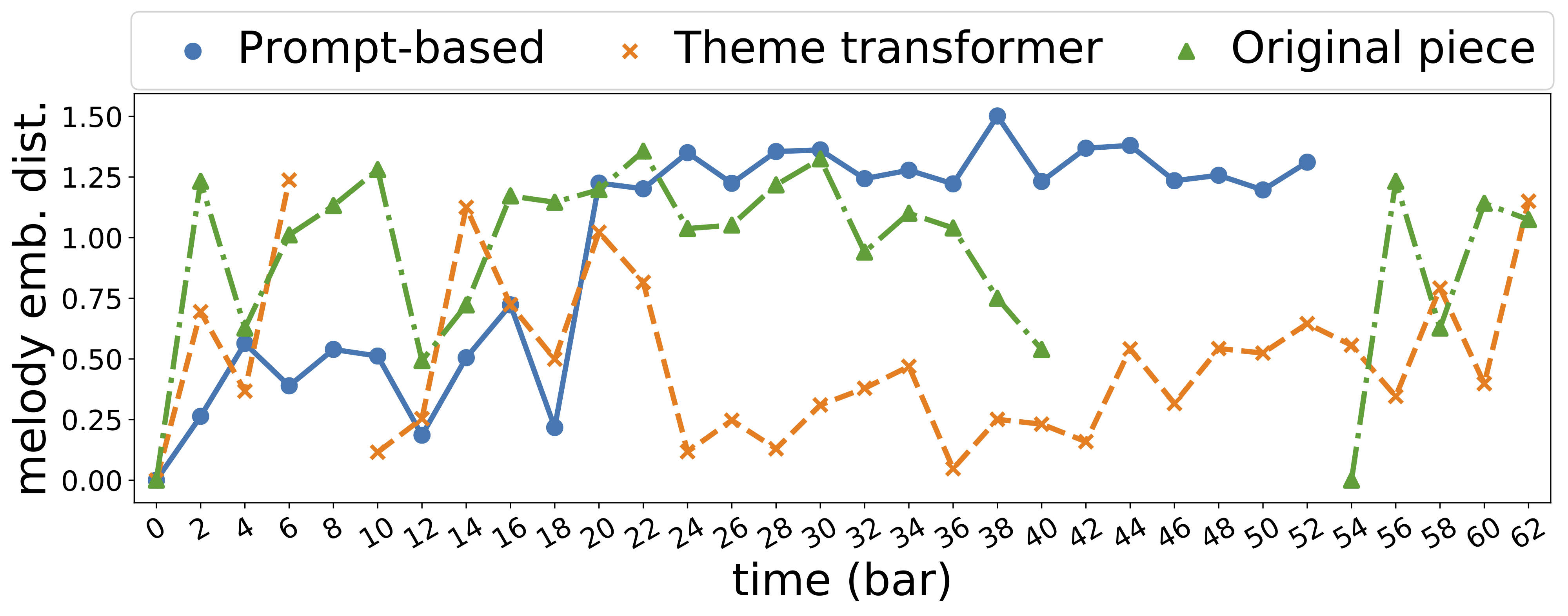 |
| 900 |  |
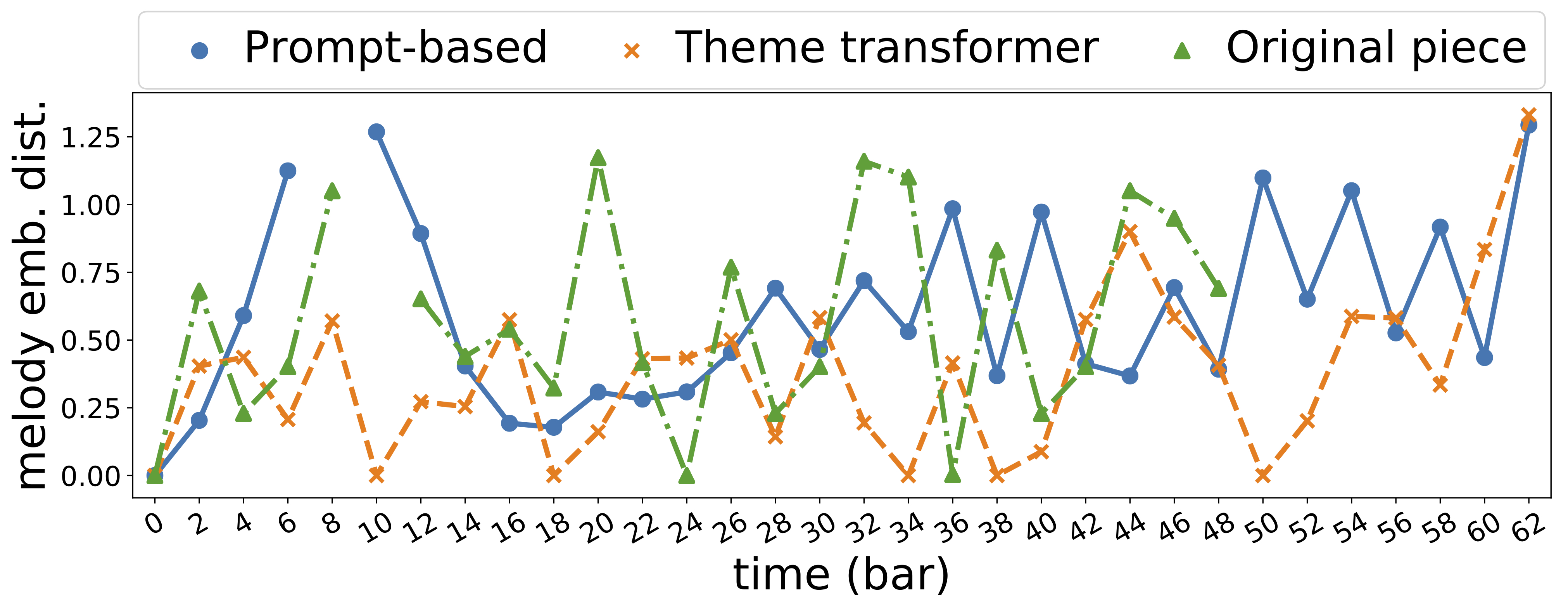 |
| 901 |  |
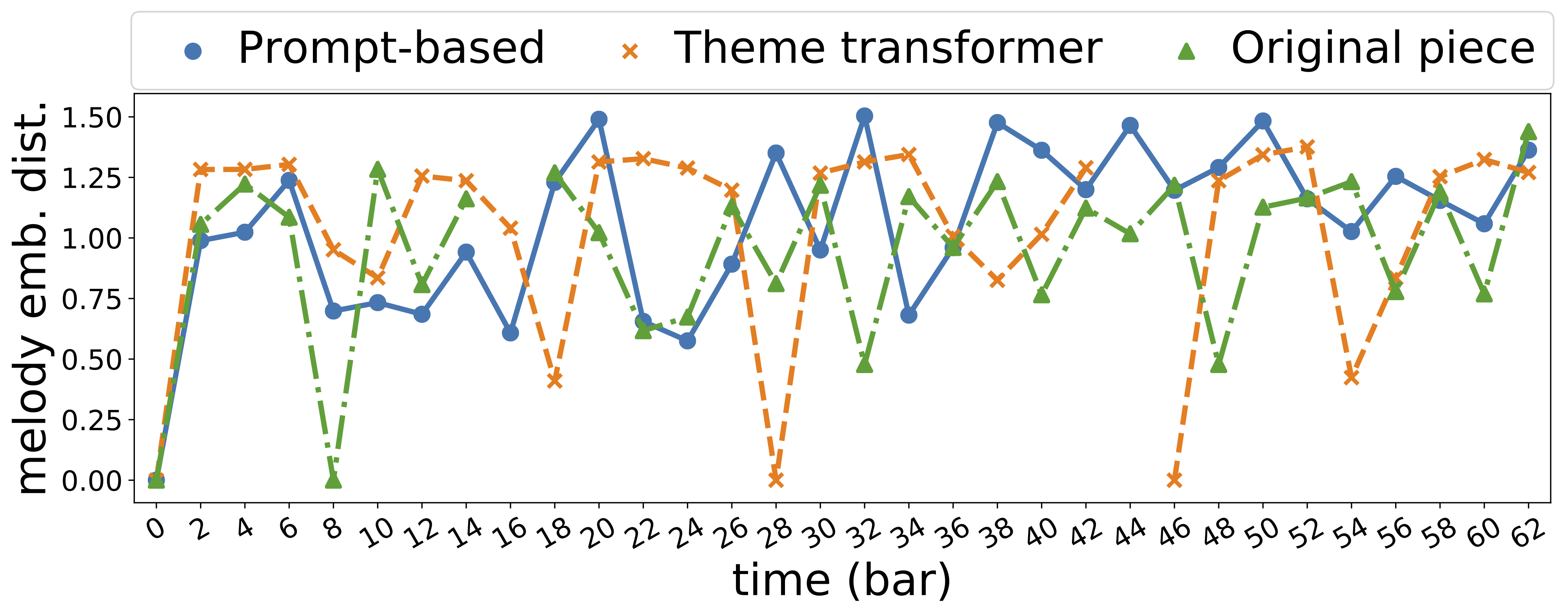 |
| 904 |  |
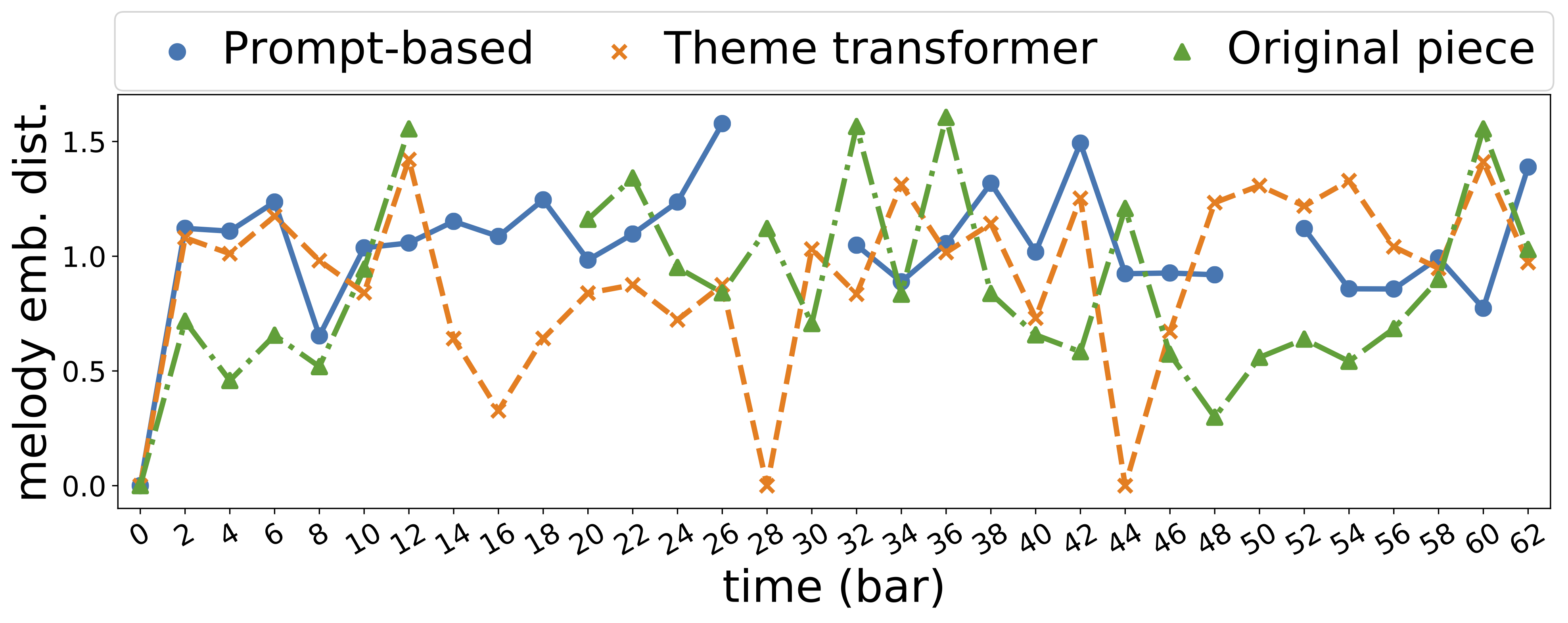 |
| 908 |  |
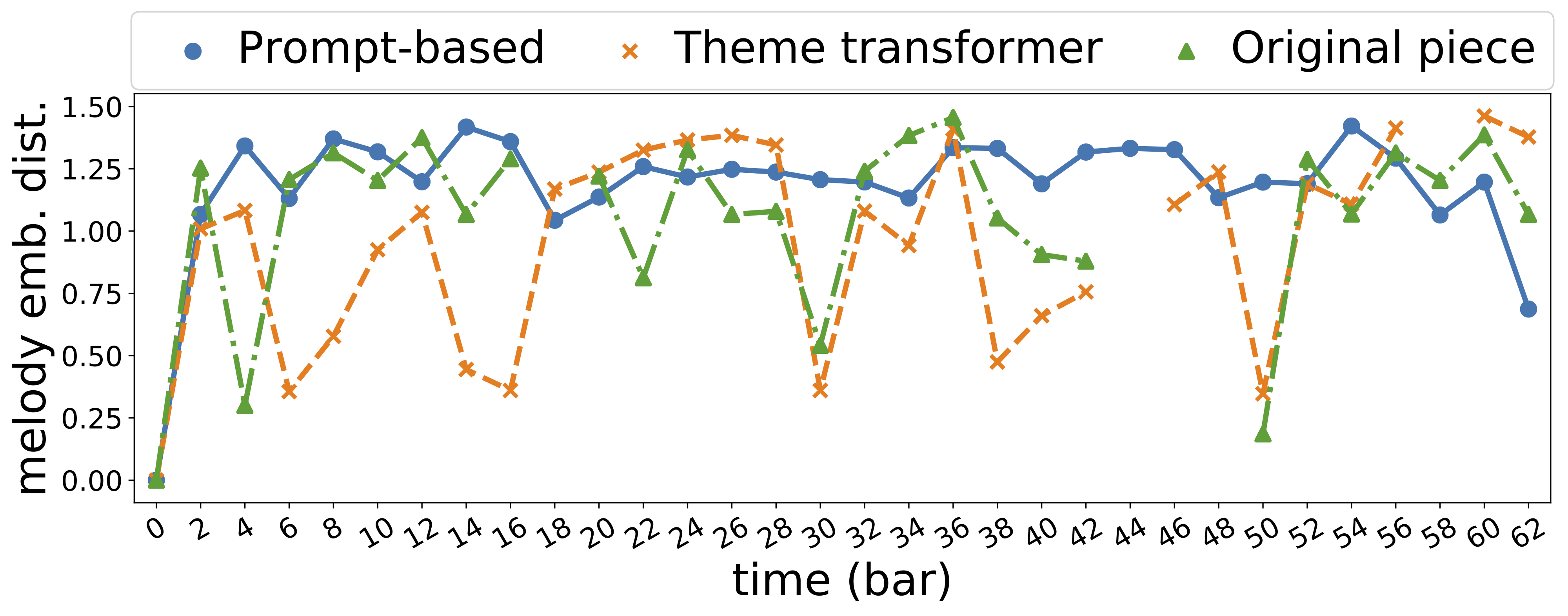 |
| 909 |  |
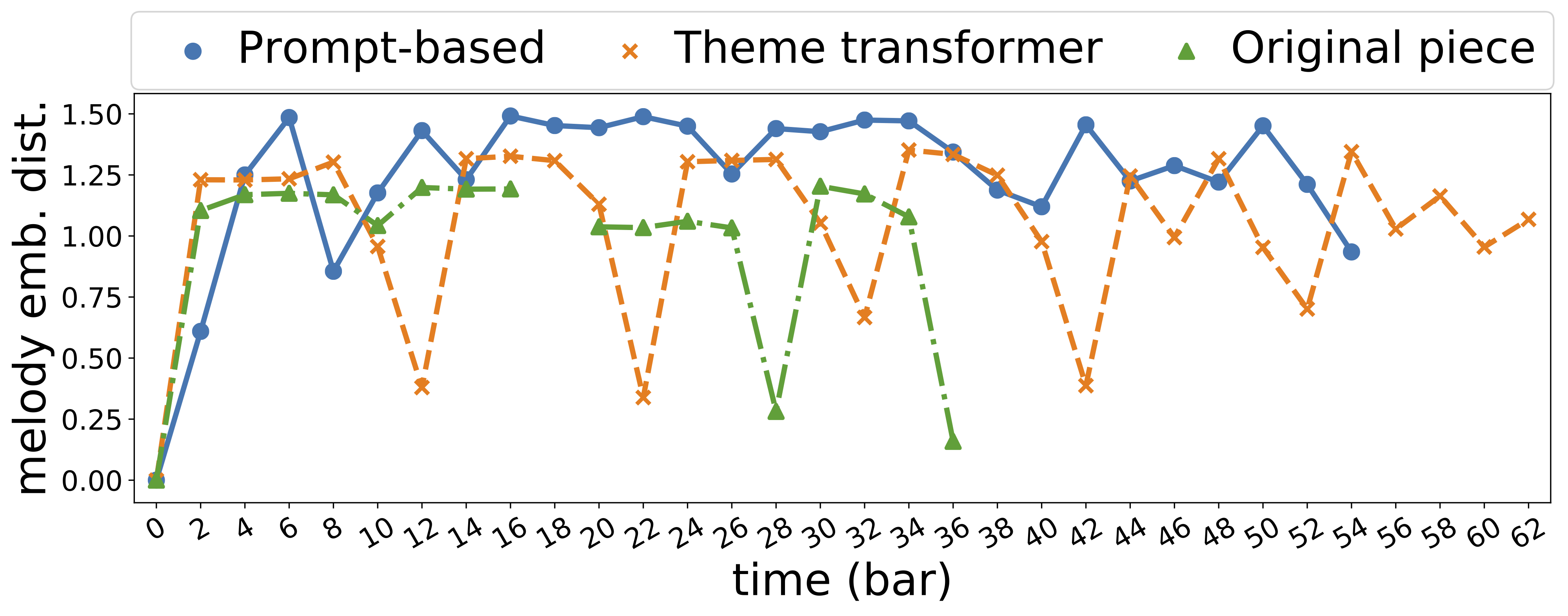 |
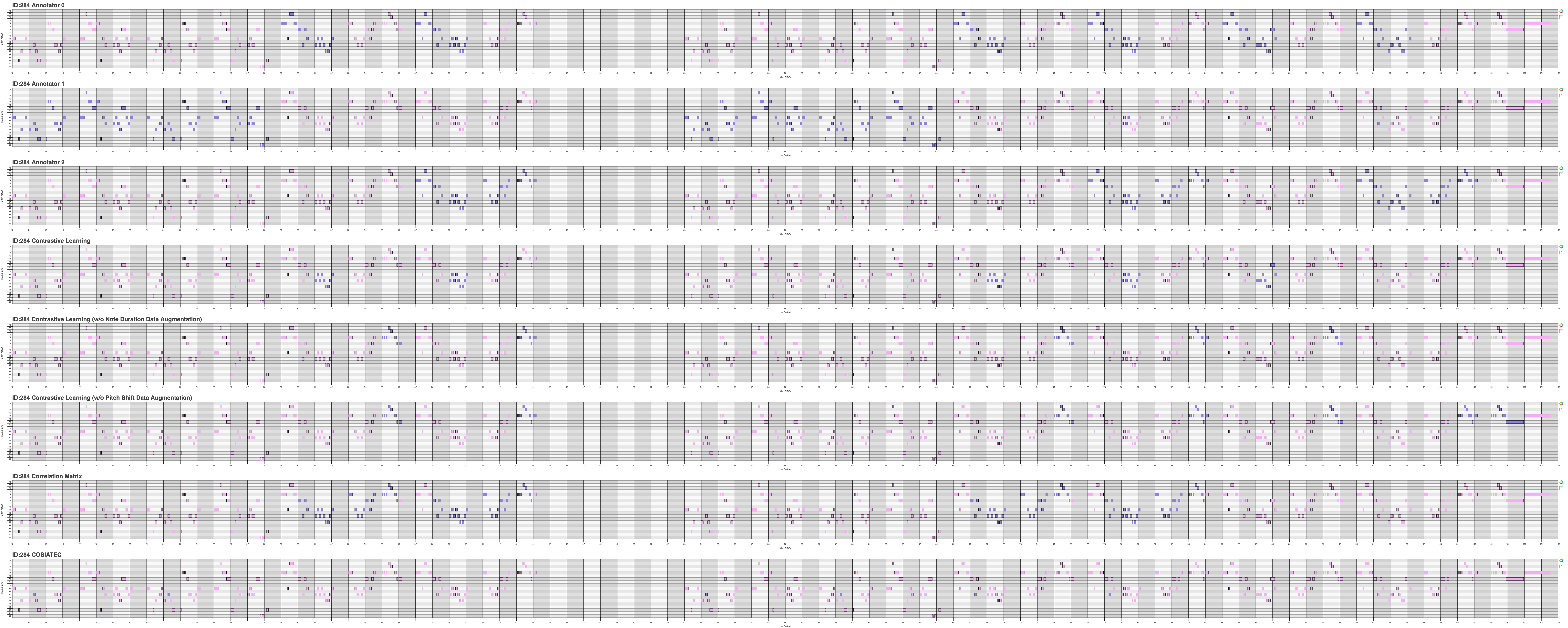
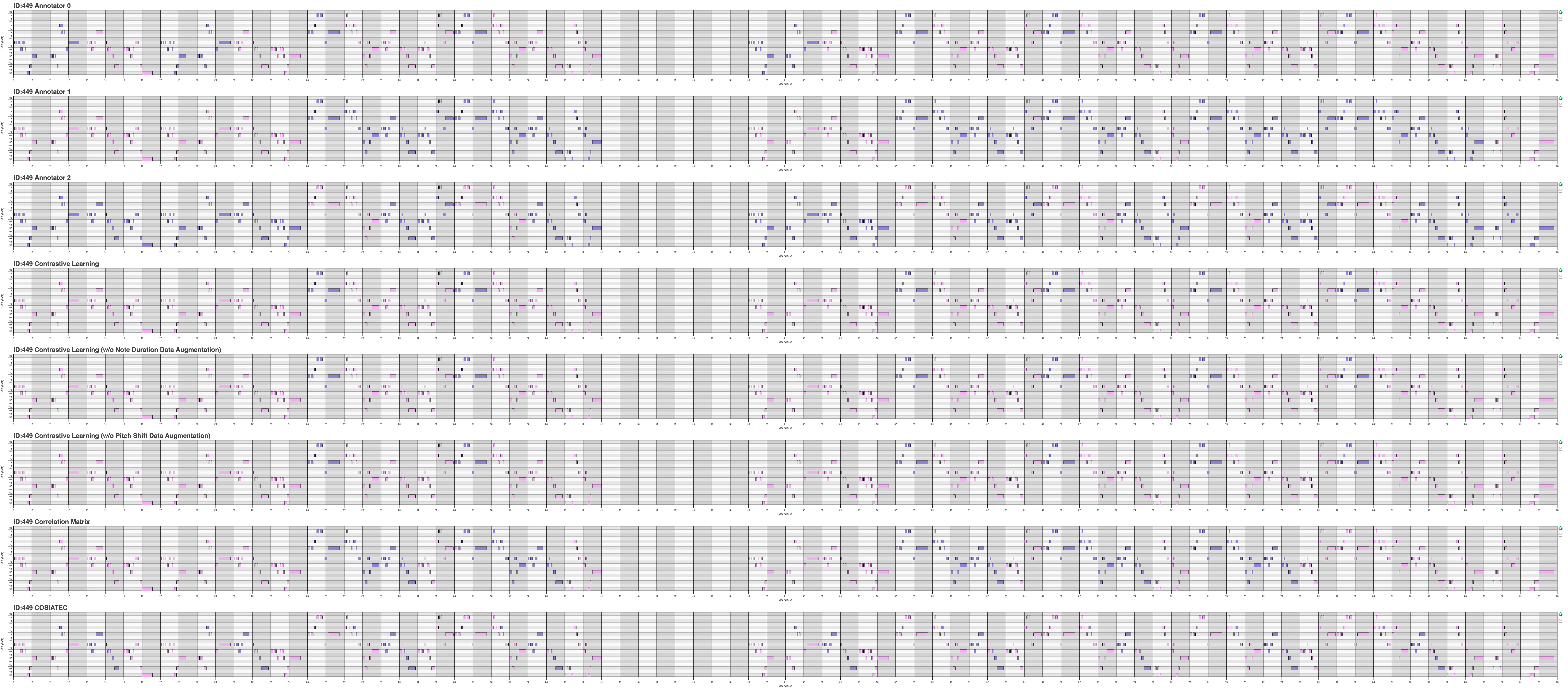
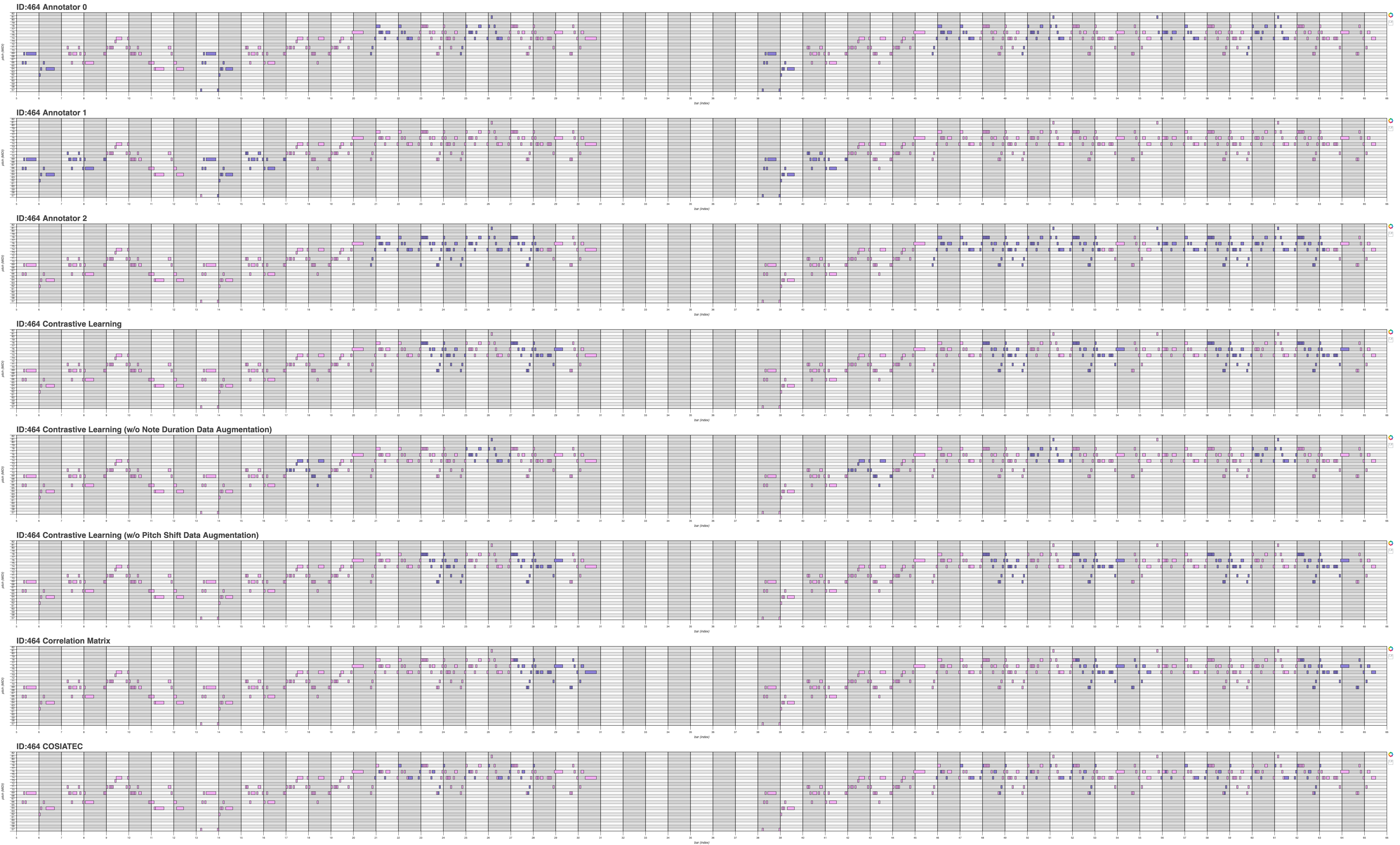
Qualitative results for Theme Retrieval
For more details about Theme Retrieval: link
| Midi ID | Piano Roll (.png) | Piano Roll (webpage) | Midi Files |
|---|---|---|---|
| 065 | Link | Link | Link |
| 284 | Link | Link | Link |
| 310 | Link | Link | Link |
| 422 | Link | Link | Link |
| 449 | Link | Link | Link |
| 464 | Link | Link | Link |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comparision for Different Sampling Temperature on Inference phase
File: temperature_comparison.zip
Comparision for Different Eps in DBSCAN
File: eps_comparison.zip
Citation
If you find this work helpful and use our code in your research, please kindly cite our paper:
@article{shih2021theme,
title={Theme Transformer: Symbolic Music Generation with Theme-Conditioned Transformer},
author={Yi-Jen Shih and Shih-Lun Wu and Frank Zalkow and Meinard Müller and Yi-Hsuan Yang},
year={2021},
eprint={2111.04093},
archivePrefix={arXiv},
primaryClass={cs.SD}
}